Announcing the new Jupyter Book#
Note: this announcement is cross-posted between the Jupyter Blog and the Executable Book Project updates blog
Jupyter Book is an open source project for building beautiful, publication-quality books, websites, and documents from source material that contains computational content. With this post, we’re happy to announce that Jupyter Book has been re-written from the ground up, making it easier to install, faster to use, and able to create more complex publishing content in your books. It is now supported by the Executable Book Project, an open community that builds open source tools for interactive and executable documents in the Jupyter ecosystem and beyond.
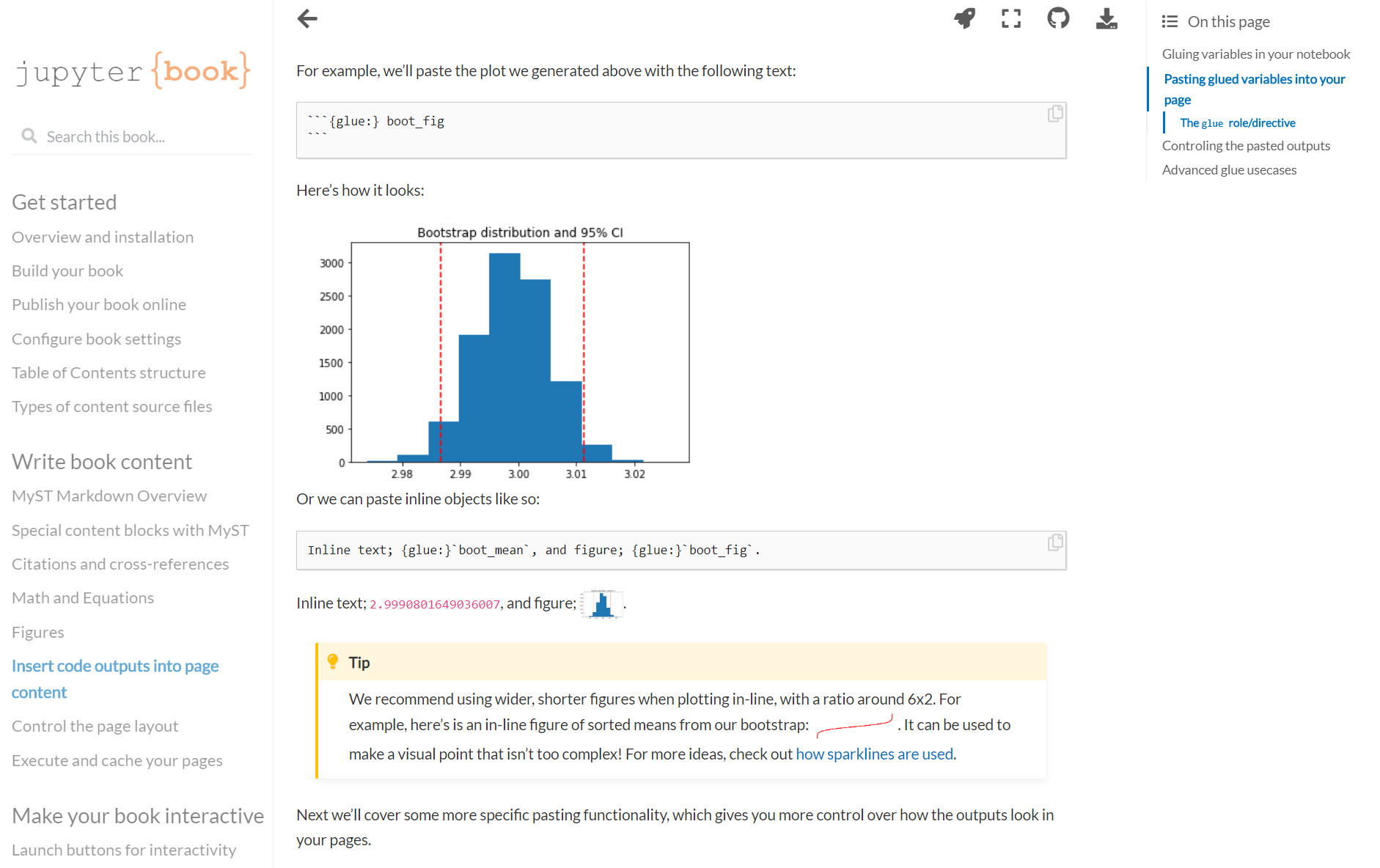
The new Jupyter Book interface, highlighting how you can insert code outputs into your content#
This post is a short overview of the new features in Jupyter Book, and gives some background on the future of the project.
You can also browse the new Jupyter Book documentation, or check out the Jupyter Book GitHub repository.
Note
Jupyter Book is still in beta, so things are always changing. We’d love your feedback, ideas, and PRs for how to make the project better!
What does the new Jupyter Book do?#
The new version of Jupyter Book will feel very similar. However, it has a lot of new features due to the new Jupyter Book stack underneath (more on that later).
The new Jupyter Book has the following main features (with links to the relevant documentation for each):
Write publication-quality content in markdown
You can write in either Jupyter markdown, or an extended flavor of markdown with publishing features.
This includes support for rich syntax such as citations and cross-references, math and equations, and figures.
Write content in Jupyter Notebooks
This allows you to include your code and outputs in your book.
You can also write notebooks entirely in markdown to execute when you build your book.
Execute and cache your book’s content
For .ipynb and markdown notebooks, execute code and insert the latest outputs into your book.
In addition, cache and re-use outputs to be used later.
Insert notebook outputs into your content
Generate outputs as you build your documentation, and insert them in-line with your content across pages.
Add interactivity to your book
You can toggle cell visibility, include interactive outputs from Jupyter, and connect with online services like Binder.
Generate a variety of outputs
This includes single- and multi-page websites, as well as PDF outputs.
Build books with a simple command-line interface
You can quickly generate your books with one command, like so: jupyter-book build mybook/
These are just a few of the major changes that we’ve made. For a more complete idea of what you can do, check out the Jupyter Book documentation
Major changes#
In the next few sections we’ll talk about some major changes that you may notice in Jupyter Book.
An enhanced flavor of markdown#
The biggest enhancement to Jupyter Book is support for the MyST Markdown language. MyST stands for “Markedly Structured Text”, and is a flavor of markdown that implements all of the features of the Sphinx documentation engine, allowing you to write scientific publications in markdown. It draws inspiration from RMarkdown and the reStructuredText ecosystem of tools. Anything you can do in Sphinx, you can do with MyST as well.
MyST Markdown is a superset of Jupyter Markdown (AKA, CommonMark), meaning that any default markdown in a Jupyter Notebook is valid in Jupyter Book. If you’d like extra features in markdown such as citations, figures, references, etc, then you may include extra MyST Markdown syntax in your content.
For example, here’s how you can include a citation in the new Jupyter Book:
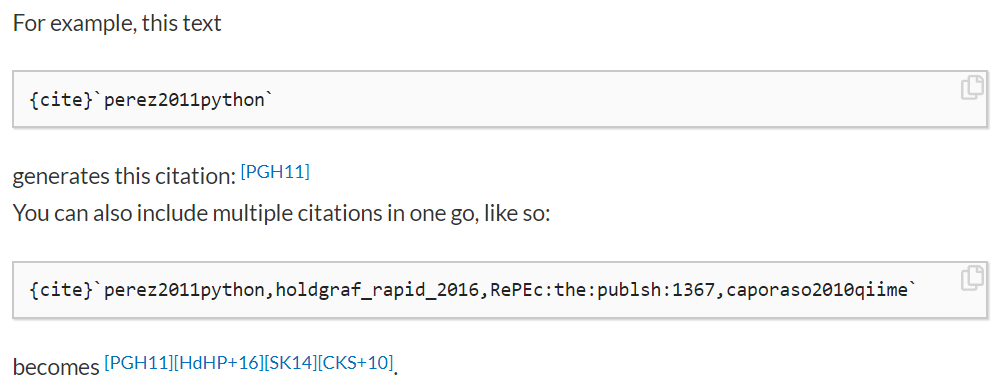
A sample citation. Here we see how you can include citation syntax in-line with your markdown, and then insert a bibliography later on in your page.#
And here’s how you can include a figure:
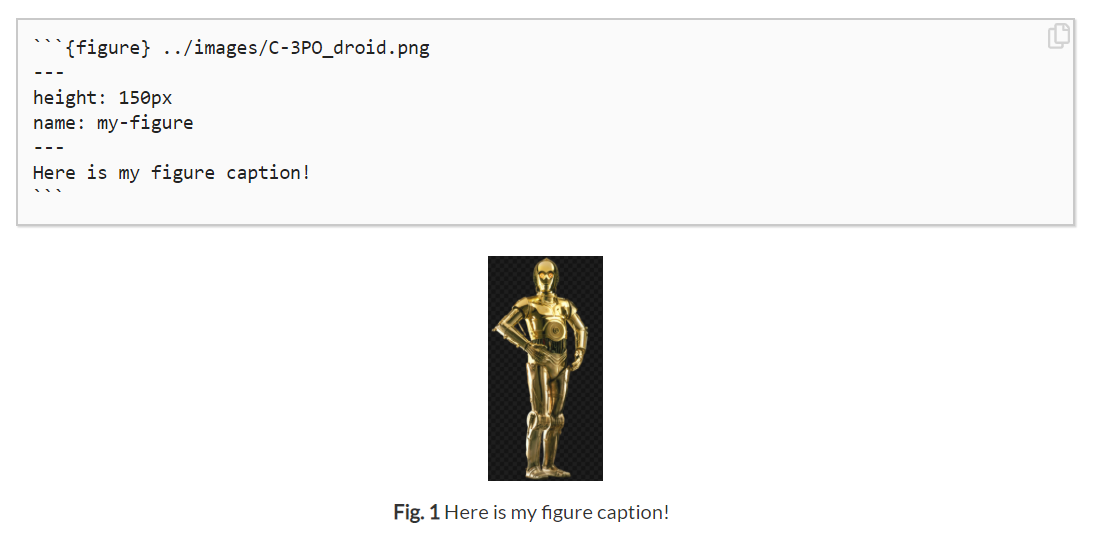
A sample figure. Here we see how you can insert a figure with a caption into your book, and control some aspects of how the figure is displayed with options.#
A smarter build system#
While the old version of Jupyter Book used a combination of Python and Jekyll to build your book’s HTML, the new Jupyter Book uses Python all the way through. This means that building the HTML for your book is as simple as:
jupyter-book build mybookname/
In addition, the new build system leverages Jupyter Cache to execute notebook content only if the code is updated, and to insert the outputs from the cache at build time. This saves you time by avoiding the need to re-execute code that hasn’t been changed.
An example build process. Here the jupyter-book command-line interface is used to convert a collection of content into an HTML book.#
More book output types#
By leveraging Sphinx, Jupyter Book will be able to support more complex outputs than just an HTML website. For example, we are currently prototyping PDF Outputs, both via HTML as well as via LaTeX. This gives Jupyter Book more flexibility to generate the right book for your use case.
You can also run Jupyter Book on individual pages. This means that you can write single-page content (like a scientific article) entirely in Markdown.
A new stack#
The biggest change under-the-hood is that Jupyter Book now uses the Sphinx documentation engine instead of Jekyll for building books. By leveraging the Sphinx ecosystem, Jupyter Book can more effectively build on top of community tools, and can contribute components back to the broader community.
Instead of being a single repository, the old Jupyter Book repository has now been separated into several modular tools. Each of these tools can be used on their own in your Sphinx documentation, and they can be coordinated together via Jupyter Book:
The MyST markdown parser for Sphinx allows you to write fully-featured Sphinx documentation in Markdown.
MyST-NB is an
.ipynbparser for Sphinx that allows you to use MyST Markdown in your notebooks. It also provides tools for execution, cacheing, and variable insertion of Jupyter Notebooks in Sphinx.The Sphinx Book Theme is a beautiful book-like theme for Sphinx, build on top of the PyData Sphinx Theme.
Jupyter Cache allows you to execute a collection of notebooks and store their outputs in a hashed database. This lets you cache your notebook’s output without including it in the
.ipynbfile itself.Sphinx-Thebe converts your “static” HTML page into an interactive page with code cells that are run remotely by a Binder kernel.
Finally, Jupyter Book also supports a growing collection of Sphinx extensions, such as sphinx-copybutton, sphinx-togglebutton, and sphinx-panels.
We’ll write a more developer-focused post in the future to describe each of these components in more detail.
What next?#
Jupyter Book and its related projects will continue to be developed as a part of the Executable Book Project, a community that builds open source tools for high-quality scientific publications from computational content in the Jupyter ecosystem and beyond.
If you’d like to learn more about Jupyter Book or get started building your own books, then check out the new Jupyter Book documentation. Jupyter Book is still in beta and is constantly being improved, so your feedback and contributions are always welcome.
If there are particular features you’d like to see, open an issue or give a 👍 to a pre-existing issue, and it will be bumped up on the feature request leaderboard.
Get involved#
If you’d like to contribute to any of the projects listed in this post, you are highly encouraged to do so! The Executable Book Project (and thus Jupyter Book) is run as an open project that welcomes contributions from others.
We are excited about all the new features and improvements in the new Jupyter Book, and look forward to seeing the new books that the community creates with this stack!